Rebound Feature
Description
Rebound is a feature which adds a possibility to bounce back and reprocess the incoming messages when the system is not ready to process them at that particular instance.
Use case of Rebound
Let us consider synchronization of products and prices between complex systems like ERP and Shop. These two different systems also have different hierarchical structures for products and prices. For this purposes they are synched separately using two parallel processes. One process syncs products, the other syncs the prices for the products.
Connecting two separate systems can cause delays in any of single processes which could result in data loss. For example in the event when the price information arrives couple of seconds earlier than the product description is on the place then there is nothing to tie the price to and an error will occur. To address this situation and make the synchronization faultless the price information is sent back or rebounded as many times until the product description is synched. This is done with a hope that the product information would eventually be synched by a separate process.
How the Rebound works?
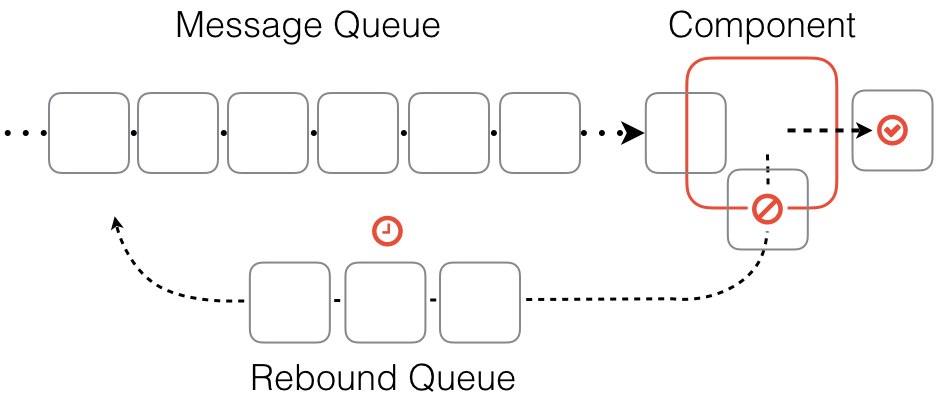
When the message can not be processed by the component due to the insufficient information then it is sent back or rebounded. This means that the message is sent to a special queue where it waits for a minute and then re-queued for a repeated processing by the component. In case that the message is rebounded again then the waiting period is consequently increased with each iteration. This process can happen several times (currently it’s set to repeat 10 times), after which the message is rejected completely and an error is reported.
The practical need for eventual consistency
Here is how the problem can happen in practice. We have a task to synchronise orders and customers between two complex systems like ERP and online shop.
-
Customers register in shop and place their orders.
-
Each order contains a reference to a customer, so that no order could be created in ERP before customer is created.
Two separately running parallel integration processes are created:
- Process A synchronizes customers and
- Process B synchronizes the corresponding orders.
As two processes are running in parallel, we could run into a situation when an order arrives earlier than the corresponding customer data. This would prevent that particular order from being created in ERP and could potentially lock the system blocking the further processing. This is a simple example of hierarchical data structures with inter-dependencies that require some safeguarding to ensure consistency in the distributed systems (ERP & Shop).
The theory behind the eventual consistency
In theoretical computer science we are faced with the uncertainty of three states which are the Consistency, Availability and Partition tolerance (the CAP theorem). For a distributed computer system it is impossible to guarantee all three states simultaneously. One or two of these states would need to be sacrificed if one would try to seek an absolution in one state only. Instead, synergy or partial solutions can be devised. It is not the scope of this article to present all the solutions to this dilemma - Werner Vogels, the CTO of Amazon.com has written more on this.
Here we will talk about one of the widely accepted and used solutions in the distributed computer systems called eventual consistency:
Eventual consistency is a consistency model used in distributed computing to achieve high availability that informally guarantees that, if no new updates are made to a given data item, eventually all accesses to that item will return the last updated value. - Wikipedia, Eventual Consistency
In all its glory, eventual consistency is not a flawless solution partly because eventual consistency is a liveness guarantee. This means it can keep the system alive (free from deadlock) and progress further despite the errors. What we would need to do for safeguarding is use sets of concurrent systems to reschedule or send messages back for reprocessing. This kind of safeguarding is called the bounded bypass which is implemented at elastic.io to reach the eventual consistency for integration processes.
Reaching eventual consistency through Rebound at elastic.io
Coming back to the example above, when we try to synchronize an order in ERP while the customer data for that order is not yet in place, we’ll simply postpone the processing of that order for a while. By doing that we give the parallel process more time to synchronize customers, and hope that the corresponding customer information would eventually be synched with the ERP. This is a clear example of eventual consistency application in the integration processes. To reach the eventual consistency we use one of the built-in features of elastic.io integration platform - the Rebound.
Please note that Rebound is a feature that adds a possibility to bounce back and reprocess the incoming messages when the system is not ready to process them at that particular instance.
When the message can not be processed by the component due to insufficient information, it is sent back or rebounded. This means that the message is sent to a special queue where it waits for a minute and then re-queued for a repeated processing by the component. In case that the message is rebounded again, then the waiting period is consequently increased with each iteration. This process can happen several times (currently it’s set to repeat 10 times in our system), after which the message is rejected completely and an error is reported.
This simple yet powerful solution ensures eventual consistency in integration processes which does not require a central coordinator (e.g. XA transaction manager, or distributed locking). It is highly available, but at the same time, one needs to understand its drawbacks, e.g. in our sample the data synchronization may happen out-of-order and get delayed.